| 边缘计算出现的背景 过去这么多年,科技行业里一直有个词很流行,这就是「大数据」。在英文世界,关于大数据「big data」也有一个恶俗但也不失精准的比喻:
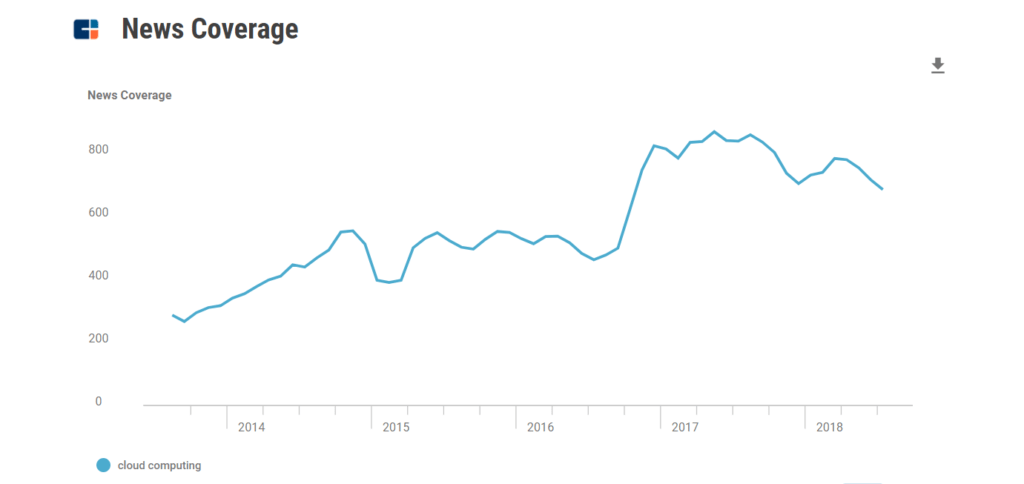
从技术发展的角度去看,这段调侃的核心还是对如何处理大数据的不解和困惑。事实上,当 2006 年亚马逊推出第一个云服务的时候,整个世界还没有被数据包围。一年后,iPhone 的出现以及随后 Android 手机「集团军」的崛起,数据被这些移动设备大批次地生产出来,紧接着,IoT、联网汽车以及智能音箱等消费市场的产品,当然还有不同垂直领域里的工业级应用,都成为更多元化的数据生成器。 这些海量的数据被不断生产出来,然后不同的公司、开发者再经过或简单或复杂的过程将数据搬运到公有云的数据仓库之中,接下来,这些公司和开发者则使用云服务商――亚马逊、微软、阿里云、Google――提供的各种数据分析、挖掘工具,从中找出「insight」。 某种意义上说,移动互联网加速了大数据进程,而大数据又推动了云计算的发展,过去十年的科技发展史,移动互联网、大数据以及云计算共同写下了浓墨重彩的一笔。 在 CBinsights 的数据库里,2019 年全球 IoT 市场预计达到 17000 亿美元,这个巨大的市场规模也意味着将有海量的数据需要处理,也进一步刺激了云计算公司的发展,下图是关于云计算的新闻热度。
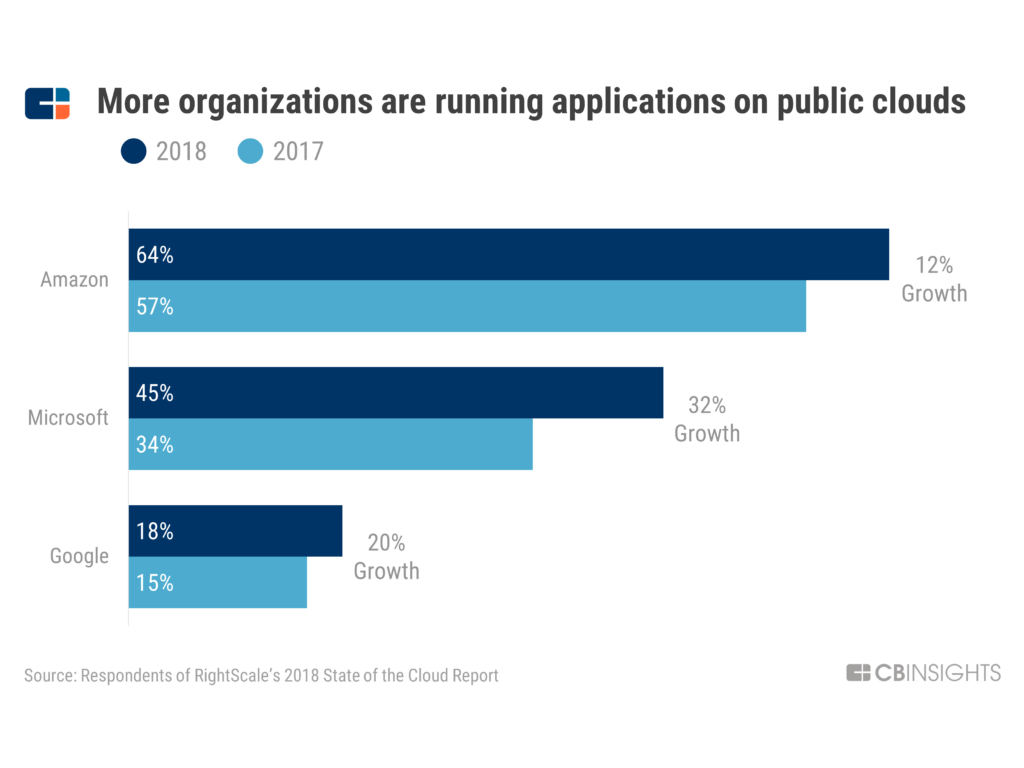
更进一步,云计算公司,尤其是主打公有云的公司,也进入到发展的快车道,下图是美国三大公有云公司过去两年客户增长状况。
但随着数据量的继续增加以及数据处理多样化的要求,基于云端的大数据处理面临诸多挑战。 以当下火热的自动驾驶汽车为例,从产品形态上看,自动驾驶汽车更像是一个「移动数据中心」。由于配备了非常多的传感器,汽车随时随地都在感知周围环境,从而源源不断地产生数据。汽车需要将这些数据实时处理,形成汽车行驶过程的指令。
比如当汽车感知到右侧有车流汇入时,就需要实时计算出车速、车距(包括与右侧、左侧、前、后),进而下达指令,或是减速,或是并道,这一系列复杂的计算过程必须实时而且还需要低延时。此时,如果数据在云端服务器处理,那么数据传输过程中的任何的延时都可能导致一场车祸的发生。 类似这样的数据处理需求正在变得越来越多,比如普通人类个体每天产生的数据量也以惊人的速度增长。预计到 2020 年,普通人每天平均产生 1.5GB 的数据,这些数据可能来自于智能手表、手环收集的运动数据,也可能来自智能手机收集的交通数据以及你浏览网页、社交媒体等产生的 Cookie 数据等等。 新的数据需求也催生了新的技术/商业模式,这便是最近一两年来「边缘计算(Edge computing )」所产生的大背景。 边缘计算的优势 在边缘计算的发展过程中,还有一个概念值得注意,这就是所谓「雾计算(fog computing)」。 这两个概念有容易混淆。「雾计算」更强调在设备的网关里处理数据,数据被「雾计算」收集到设备的网关,进而处理、存储,并将处理后的数据发挥需要数据的设备中。 而边缘计算更强调「边缘」,也就是更靠近数据生成的设备端,「雾计算」则介于云计算和边缘计算之间。 这也意味着,边缘计算有着诸多「先天优势」,其一,更实时、更快速的数据处理能力。由于减少了中间传输的过程,数据处理的速度也更快。 其二,成本更低。边缘计算处理的数据是「小数据」,从数据计算、存储上都具有成本优势。 其三,更低的网络带宽需求。随着联网设备的增多,网络传输压力会越来越大,而边缘计算的过程中,与云端服务器的数据交换并不多,因此也不需要占用太多网络带宽; 第四,提升应用程序的效率。结合上面的三个优势来看,当数据处理更快、网络传输压力更小、成本也更低的时候,应用程序的效率也会大大提升。 第五,边缘计算让数据隐私保护变得更具操作性,这在今年 5 月欧盟通过史上最严格的数据保护法律之后意义重大。由于数据的收集和计算都是基于本地,数据也不再被传输到云端,因此重要的敏感信息可以不经过网络传输,能够有效避免传输过程中的泄漏。 边缘计算的玩家们 下图里,你会发现边缘计算的新闻关注度从 2017 年开始变得越来越高。
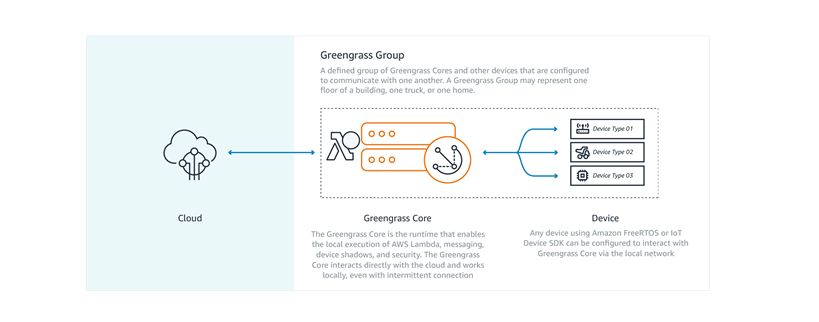
边缘计算的几个重要玩家也是公有云的巨头,亚马逊、微软、Google 先后有自己的布局。 亚马逊在 2017 年推出了 AWS Greengrass,这是一个可以将亚马逊 AWS 服务部署到终端设备的产品。官方称,通过 Greengrass,可以实现本地数据收集、处理,同时云端还可以继续管理数据。
微软在 2018 年 Build 大会上将边缘计算作为一个重中之重,我曾在 5 月的会员通讯里作出过分析:
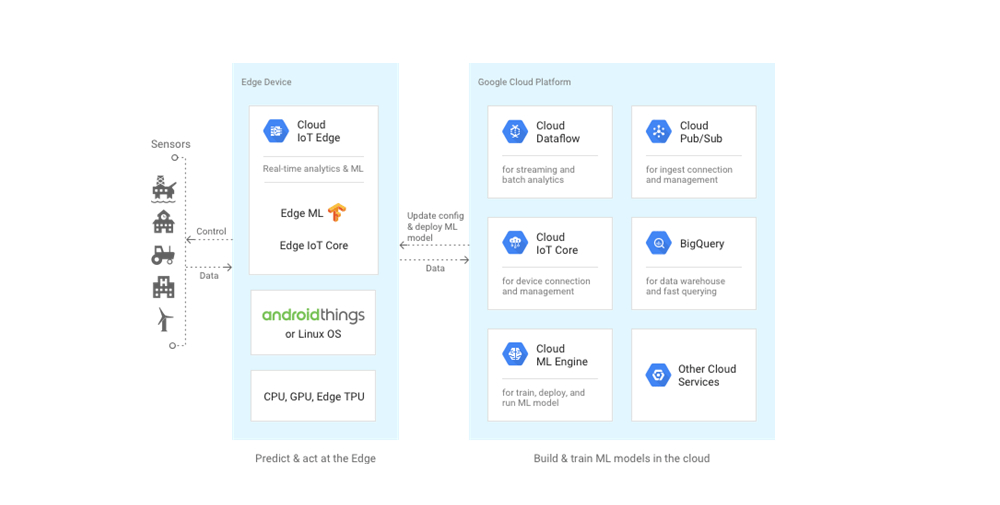
Google 则在今年 Google Cloud Next 大会期间发布了两个产品:云端芯片 Edge TPU(硬件)和软件工具 Cloud IoT Edge(软件)。Google Cloud 官方这样介绍两个产品:
除此之外,还有很多科技巨头加入到边缘计算的赛场。比如惠普企业(Hewlett Packard Enterprise)就表示将在未来四年投资 40 亿美元用于边缘计算。惠普企业的边缘计算产品名叫「Edgeline Converged Edge Systems」,其主要客户群体是工业领域,比如油田、煤矿等,这些特定行业的工作环境里,无法满足云端数据的处理条件,因此边缘计算就成为一个重要需求。 今年 4 月的云栖大会深圳峰会上,阿里云掌舵者胡晓明代表阿里巴巴宣布进军物联网,并将物联网作为电商、金融、物流、云计算之后的「新赛道」。 战略层面,胡晓明提了一个「小目标」,阿里云计划在未来 5 年内连接 100 亿台设备。而在战术上,阿里希望「打通云、边、端,整合包括物联网操作系统 AliOS Things、IoT 边缘计算产品、通用物联网平台,实现物的实时决策和自主协作。」 不过,阿里巴巴在国内将面临华为的巨大压力,在阿里巴巴发布物联网计划之后,华为的发布了一个意味深长的图片。
边缘计算的应用场景 微软 CTO Kevin Scott 曾坦言,边缘计算还处在相对早期阶段。但透过这段时间内的场景落地状况,我们也可能窥见边缘计算的潜力。 如上文所言,自动驾驶成为边缘计算领域重要的行业应用,下图是英特尔对于自动驾驶汽车上的「数据洪流」的描述。
不过,当下自动驾驶也处在早期阶段,车联网或者联网汽车则是汽车领域可以马上落地的场景。 在国内,不管是阿里旗下的斑马网络还是百度的小度车载,都在将汽车变成一种「移动的数据中心」,只是相对于自动驾驶,联网汽车的数据量和处理要求要简单很多。即便如此,由于汽车的数据处理不能出现任何的卡顿和延迟,这也就需要在汽车里部署数据处理能力。 另一个应用场景则是医疗。前几年风靡一时的所谓智能手环,本质上就是一个数据采集器,但是由于需要和云端服务器进行数据交换,使得整个手环的「智商」几乎为零。 随着苹果发布 Apple Watch 所带来的新穿戴设备潮流,这些边缘设备也终于开始拥有了自己的芯片,并能实现一些简单的计算。医生也可以通过这些计算结果作出一些简单诊断。 更进一步,在美国,医疗领域的本地数据非常多样化,比如医院的病床可以和 20 多个设备连接,这些数据被收集、清洗、挖掘之后,可以帮助医生更好地了解病人的身体状况。
工业领域,边缘计算也正在发挥越来越重要的作用。从工业发展的方向来看,数据将成为驱动生产制造的重要生产资料,那么如何处理这些海量、实时产生的数据就成为企业能否快速发展的重要课题。 以流程型生产为例,一条生产线其实就是数据流动的通道,产品从上一名工人传递到下一个工人,同时伴随着产品数据的传递。在这个过程中,如果由于某一名工人错误操作的导致了数据异常,在下一名工人开始操作时,基于边缘计算的生产线可以做出预警提示。如果再进一步,当机器学习能力被边缘计算融入到生产线的时候,工人的不合规操作可以被实时监测出来并预警,这对提升产品的良品率意义重大。 尾巴:边缘计算不是云计算的替代品 前面谈了这么多边缘计算的优势和应用场景,并不是要证明边缘计算可以替代云计算,两者没有谁好谁坏,更应该具体到不同设备、不同应用以及不同场景里,看看到底谁更合适。 两年前,利用基于云端的卷积神经网络算法,,一款名叫「Prisma」迅速窜红,用户只要将自己拍摄的照片交给这个 App,就会得到一张可媲美历史名画的「艺术照片」。这款应用虽然得到全球用户的青睐,但是由于该应用的处理流程,要求每张图片都要上传到云端服务器,通过云端的卷积神经网络算法来处理这些照片,因此用户体验非常差。 这便是一个典型需要边缘计算的场景,而当 2017 年,包括华为、苹果都在新一代智能手机芯片中加入 NPU(神经网络处理单元)之后,也赋予了智能手机全新的边缘计算处理能力,华为 P20 Pro 的逆天夜拍效果,除了硬件堆积之外,处理器的 NPU 也发挥了不小的作用,去年苹果推动的 AR 应用(游戏)开发热潮,其底层的技术支撑就是 iPhone 拥有了可以在边缘处理实时、海量数据的能力。 从智能手机到可穿戴设备,从医疗到汽车以及工业制造,边缘计算正在上演一个又一个行业传奇,它的落脚点是要让终端成为更智慧的存在――能够实时处理数据、能够低延时做出反馈――这不就是我们期待中的智能设备吗? |